


When Slower is Better: Implementation and Results (Part 2)
Turning latency injection theory into cost savings - the technical deep dive

📖 This is Part 2 of a 2-part series. Read Part 1: How a Costco Queue Revolutionized Our DR Strategy for the background story and problem context.
Recap
In Part 1, we explored how a pandemic queue at Costco inspired a breakthrough in disaster recovery cost optimization. Faced with the challenge of reducing our DR compute capacity by 20% while maintaining service quality, we discovered that intentionally increasing system latency could naturally reduce throughput through client backoff behavior—the same phenomenon that caused customers to voluntarily leave long lines during COVID. Now, let's dive into how we turned this counter-intuitive insight into a production-ready solution.
Implementation Strategy
Once we decided to pursue latency injection as our throughput reduction mechanism, the real work began: figuring out exactly where and how to implement it without destroying the customer experience.
Choosing the Right Traffic Flow
The first critical decision was selecting which traffic flows would receive the latency treatment. We had to balance effectiveness with customer impact, and this required analyzing our traffic patterns carefully.
At Box, a typical customer workflow involves three main interaction patterns:
Browsing Files - High volume (>100K requests per second), millisecond-level latencies, no downstream effects. This flow represents customers navigating through their file hierarchy, checking metadata, and organizing content.
Previewing/Downloading Files - Moderate volume (10-20K requests per second), latencies already in the seconds-to-minutes range, no significant downstream effects. Customers expect these operations to take time.
Uploading Files - Lower volume (<5K requests per second), latencies in the seconds-to-minutes range, but with significant fanout effects. When customers upload files, it triggers downstream processing: virus scanning, thumbnail generation, search indexing, and often immediate downloads as users verify their uploads.
The choice became clear through this analysis:
Browsing flows were off-limits. Adding even single-digit milliseconds of delay would severely impact the snappy, responsive experience customers expect when navigating their files.
Downloads and previews were candidates, but they lacked the multiplier effect we needed for maximum impact.
Uploads emerged as the optimal target. Customers already expect uploads to take time, and the fanout effect meant that reducing upload throughput would cascade into reduced load across multiple internal systems.
Pinpointing the Injection Point
With uploads selected as our target, we needed to determine exactly where in the upload pipeline to inject the delay. Here's the simplified upload flow we analyzed:
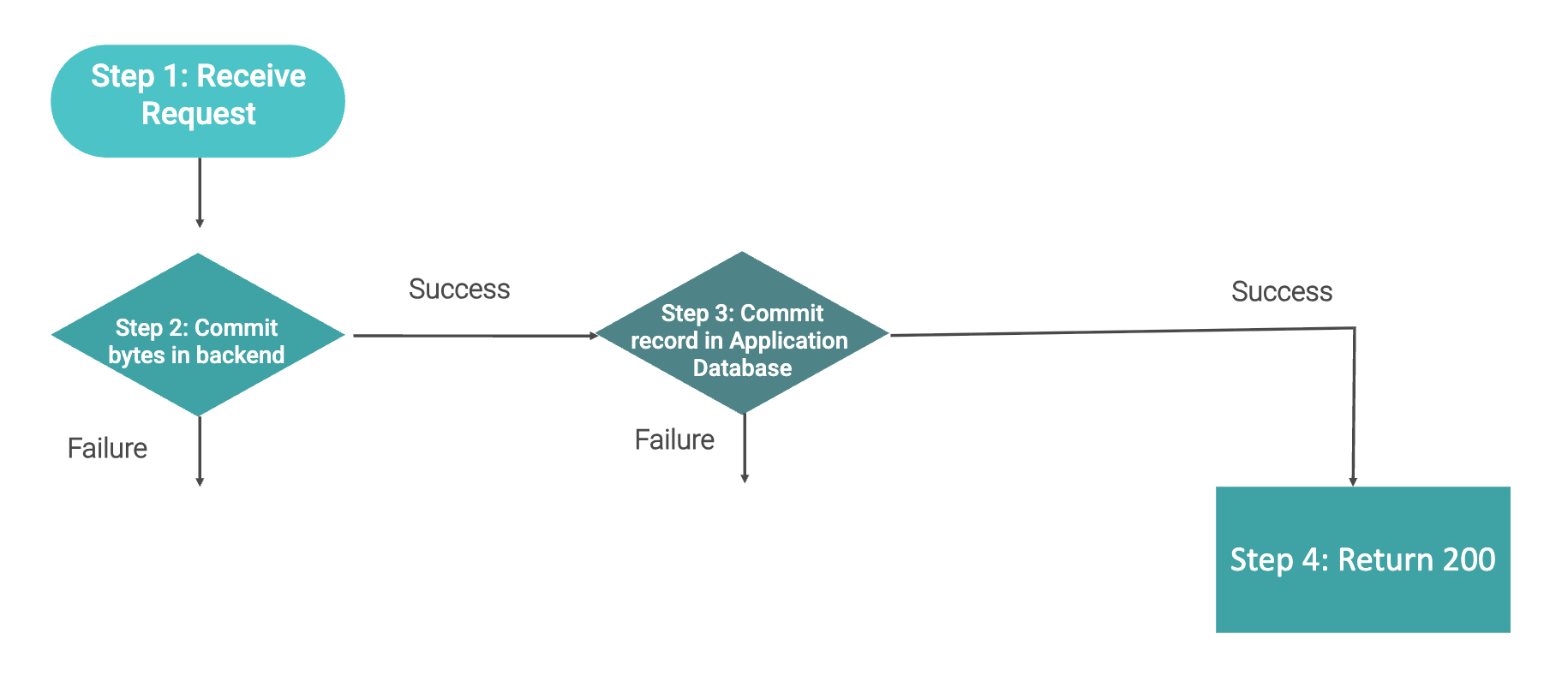
Receive upload request - Accept the request and incoming byte stream
Stream and commit bytes - Write data to backend storage
Update application database - Record the new file in our metadata systems
Return success - Confirm completion to the customer
We evaluated three potential injection points:
Between steps 1 and 2 - Delaying the byte stream itself risked unpredictable impacts on all upstream infrastructure: network edges, traffic managers, and load balancers. Clients might experience connection drops or timeouts in ways we couldn't control.
Between steps 3 and 4 - At this point, the upload has already succeeded from our perspective. There's no value in delaying the success response to the customer.
Between steps 2 and 3 - This became our sweet spot. The bytes are safely committed to storage, but the upload isn't yet "complete" from the application's perspective. Adding delay here keeps the customer's connection active (they see an in-progress upload) while giving us the throughput reduction we need.

Technical Implementation: The Non-Blocking Approach
The most naive implementation would be adding a simple Thread.Sleep() call at our chosen injection point. But this blocking approach would quickly lead to thread pool exhaustion under load—exactly the opposite of what we wanted during a disaster scenario.
Instead, we implemented the delay as a non-blocking operation. Rather than tying up threads while waiting, we used asynchronous delay mechanisms that allowed our thread pool to continue serving other requests while upload operations waited in the background.
Here's the conceptual approach:
// Instead of this (blocking):
Thread.Sleep(configuredDelaySeconds * 1000);
updateDatabase(uploadedFile);
// We implemented this (non-blocking):
await DelayAsync(configuredDelaySeconds);
updateDatabase(uploadedFile);
This pattern ensures that our latency injection doesn't become a new bottleneck that could cause system instability—the last thing you want during an actual disaster.

Why This Approach Works
The success of latency injection relies on understanding client behavior. When upload latency increases, both human users and automated systems naturally reduce their request rate:
Human Users - During the extended wait time, users often switch to other tasks, get distracted, or simply wait longer between operations. A user who might normally upload multiple files in quick succession will naturally space out their uploads when each one takes longer to complete.
Automated Clients - Most integration tools, sync clients, and API consumers have internal queues with fixed numbers of worker threads. When each upload takes longer, the overall throughput of these automated systems drops proportionally.
This client backoff behavior is what transforms our latency injection into genuine throughput reduction, creating the capacity savings we needed for cost-effective disaster recovery.
Testing and Results
With our latency injection mechanism built and configured, we faced the ultimate question: would this theoretical approach actually work in practice? More importantly, could we safely test such a fundamental change on live customer traffic without risking a production disaster?
The Production Testing Challenge
Testing capacity reduction techniques requires real client behavior—synthetic tests can't capture how humans and automated systems naturally back off when latency increases. Yet intentionally slowing down core customer workflows in production carried real risks and required winning the trust of an entire organization to get approval. This led us to develop a comprehensive framework for safely testing high-risk infrastructure changes on live traffic and building organizational confidence—which we'll cover in a future blog post.
The Results: Theory Meets Reality
The results exceeded our expectations. When we applied a 10-second delay to the upload flow, we observed a 15% reduction in CPU core utilization across Box's infrastructure. This wasn't just a localized effect—the capacity reduction cascaded through our entire infrastructure stack due to the fanout effects we had anticipated.
With 15% reduction achieved through upload delay alone, we were tantalizingly close to our 20% target. In subsequent experiments, we achieved the remaining 5% by carefully adding latency injection to one additional flow, applying the same methodical approach.
The successful validation proved that our Costco-inspired insight could translate into real infrastructure cost savings. More importantly, it demonstrated that sometimes the most effective solutions come from observing everyday phenomena and finding ways to apply those principles to complex technical challenges.
When Latency Injection Works
Mixed Client Base - You have both human users and automated systems that naturally reduce request rates when latency increases, rather than aggressively retrying failed requests.
Latency-Tolerant Operations - Target workflows where customers already expect delays: file uploads, large downloads, batch processing, or background operations.
Fanout Effects - The operation triggers downstream processing that amplifies capacity savings. Reducing upload throughput affects virus scanning, thumbnail generation, indexing, and related systems.
Success-Rate SLAs - Your service level agreements focus on success rates rather than response times, allowing you to increase latency without violating commitments.
When Latency Injection Doesn't Work
Aggressive Retry Clients - Automated systems that interpret slow responses as failures and immediately retry, potentially multiplying load rather than reducing it.
Latency-Critical Operations - Real-time interactions, financial transactions, emergency systems, or safety-critical workflows that cannot tolerate increased response times.
Benefits of This Approach
Minimal Code Changes - The implementation requires very few lines of code. As the saying goes, fewer lines of code means fewer bugs.
Limitations to Consider
Customer Experience Impact - Does affect customer experience, with the scope of impact depending on which flow receives the latency injection.
Unpredictable Correlation - It's difficult to establish a direct relationship between latency amount and CPU reduction. You may need to implement feedback loops to achieve target capacity reductions.
Delayed Effect - Takes several minutes (though less than five) from the time you add latency until you see the actual drop in throughput.
Conclusion: The Power of Counter-Intuitive Solutions
Our journey from a Costco parking lot to a 20% reduction in disaster recovery costs demonstrates how the most innovative engineering solutions often come from unexpected places. By observing natural client behavior and working with it rather than against it, we developed a technique that achieved our cost optimization goals while maintaining system reliability.
The key insight—that throughput naturally decreases as latency increases—seems obvious in retrospect. But recognizing how to apply this principle to solve a complex infrastructure challenge required stepping outside traditional approaches and being willing to experiment with counter-intuitive solutions.
As we continue to face pressure to optimize costs while maintaining high availability, techniques like latency injection offer a new dimension for capacity management. The approach isn't universally applicable, but when used in the right context with proper monitoring and controls, it can provide significant value.
Sometimes the most elegant engineering solutions are hiding in plain sight, waiting for the right moment of insight to reveal themselves. In our case, that moment came while walking away from a very long line at a warehouse store during a global pandemic.
📖 More in this series: Part 1: When Slower is Better: How a Costco Queue Revolutionized Our DR Strategy
This concludes our two-part series on using latency injection for disaster recovery cost optimization. The technique has proven valuable not just for DR scenarios, but as a general approach to capacity management during planned maintenance windows and other operational scenarios.
Questions about implementation details or want to discuss your own DR challenges? Feel free to reach out.
About the author: Advait Mishra, Engineering Manager for the Core Storage team at Box.com, responsible for building and maintaining exascale storage infrastructure. An engineering leader with expertise in distributed systems, cloud computing, and data analytics.